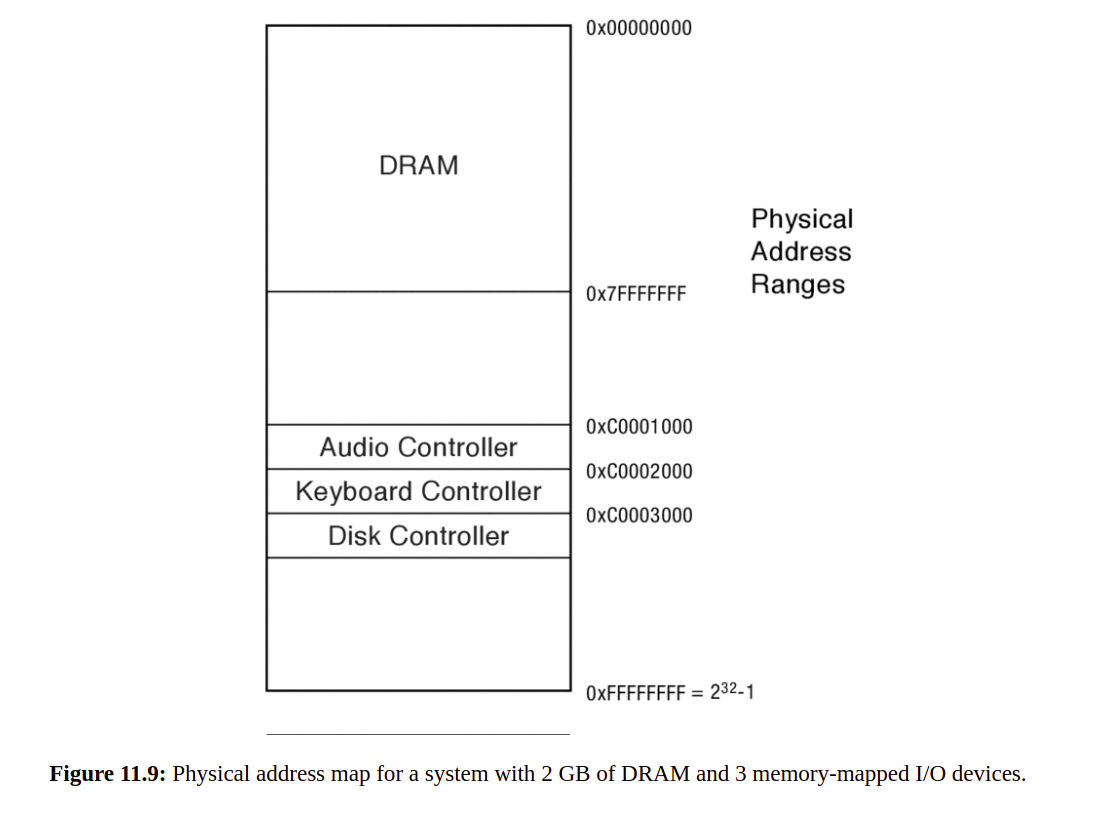
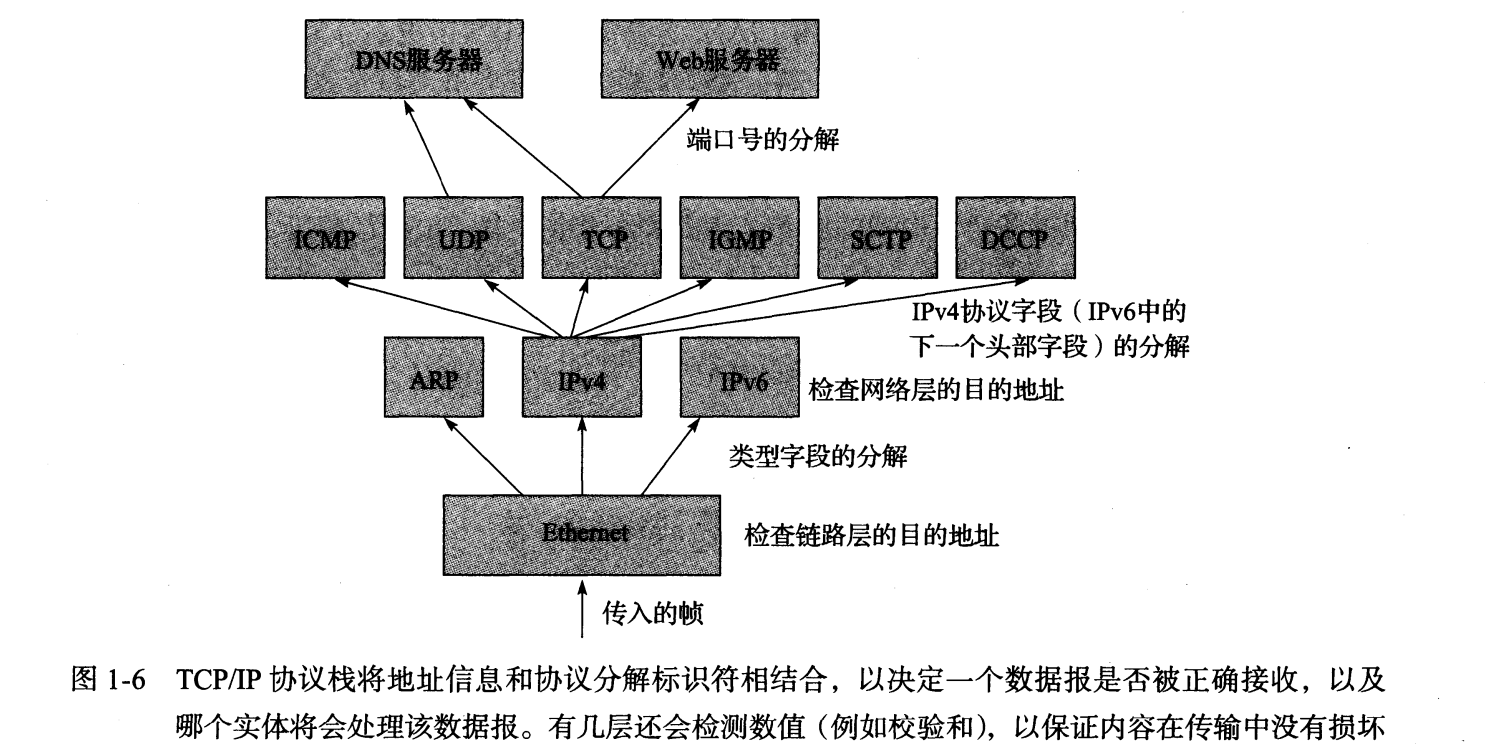
网络层及其协议IP
我们将主要讨论互联网寻址——对于理解互联网网络层的工作原理至关重要。
掌握IP寻址就是掌握互联网的网络层本身。
IPV4 数据报格式
IPv4数据报格式如图4.17所示。 IPv4数据报中的关键字段如下:
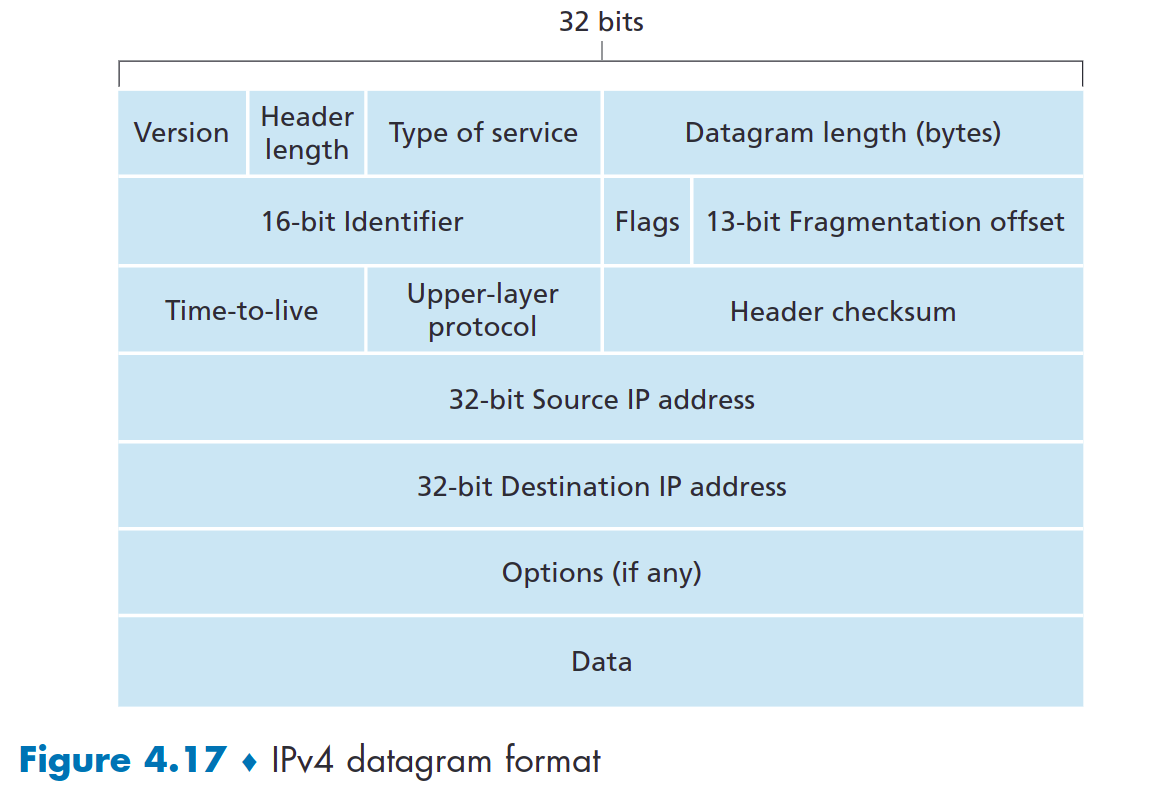
- 版本号
- 头部长度
- 服务类型
- 数据报长度
- 标识符
- 生存时间TTL
- 协议
- 头部校验和
- 源和目的IP地址
- 选项
- 数据
请注意,IP 数据报总共有 20 个字节的报头(假设没有选项)。如果数据报携带 TCP 报文段,则每个数据报携带总共 40 字节的报头(20 字节 IP 报头加 20 字节 TCP 报头)以及应用层消息。
IPv4 寻址
然而,在讨论 IP 寻址之前,我们需要先介绍一下主机和路由器如何连接到互联网。
主机通常只有一个连接到网络的链路;当主机中的 IP 想要发送数据报时,它会通过此链接进行发送。主机和物理链路之间的边界称为接口interface。
现在考虑路由器及其接口。由于路由器的工作是在一个链路上接收数据报并在其他链路上转发该数据报,因此路由器必须连接两个或多个链路。路由器与其任一链路之间的边界也称为接口。因此,路由器具有多个接口,每个接口对应其每条链路。由于每个主机和路由器都能够发送和接收 IP 数据报,因此 IP 要求每个主机和路由器接口都有自己的 IP 地址。
因此,IP 地址与接口相关联,而不是与包含该接口的主机或路由器相关联
全球互联网中每台主机和路由器上的每个接口都必须有一个全球唯一的 IP 地址(NAT 后面的接口除外,如第 4.3.3 节所述)。然而,这些地址不能随意选择。接口 IP 地址的一部分将由其连接的子网确定。
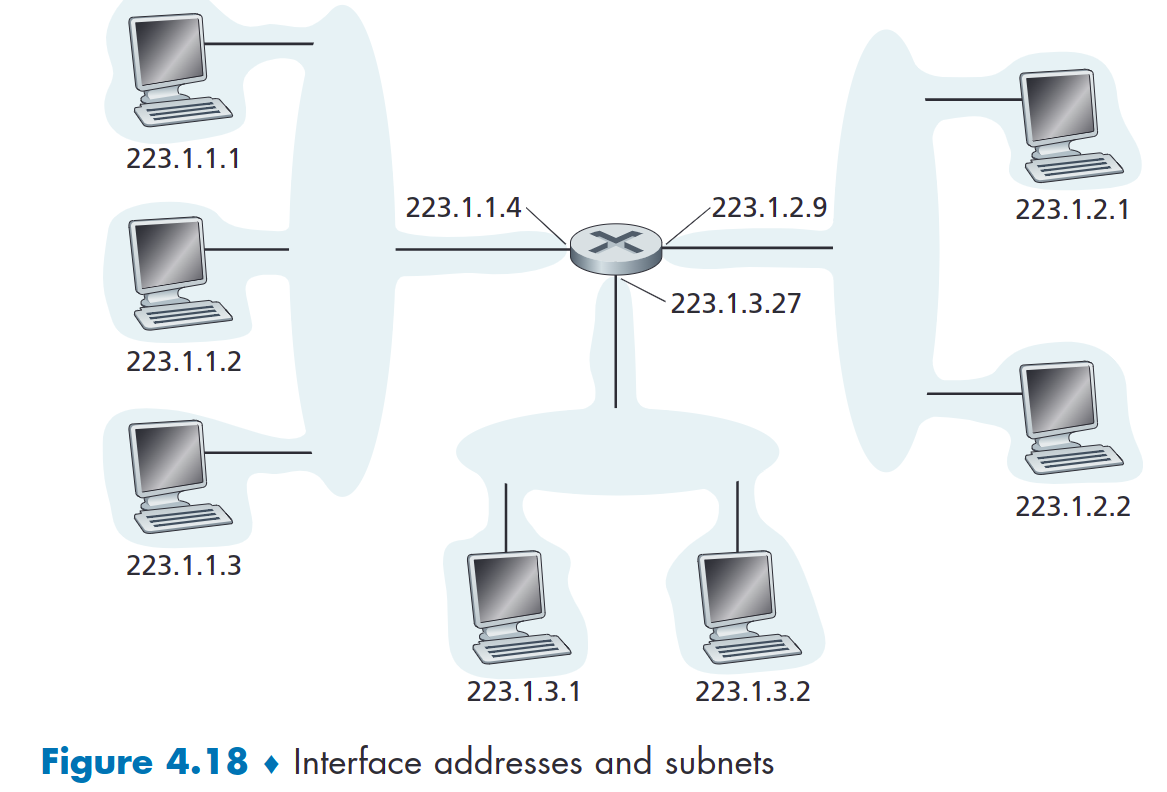
图 4.18 提供了 IP 寻址和接口的示例。在该图中,一台路由器(具有三个接口)用于互连七台主机。仔细查看分配给主机和路由器接口的 IP 地址,有几件事需要注意。
- 图 4.18 左上部分的三台主机以及它们所连接的路由器接口都具有 223.1.1.xxx 形式的 IP 地址。也就是说,它们的 IP 地址都具有相同的最左边 24 位。
- 这四个接口也通过
不包含路由器的网络相互互连。该网络可以通过以太网 LAN 互连,在这种情况下,接口将通过以太网交换机(我们将在第 6 章中讨论)或无线接入点(我们将在第 7 章中讨论)互连。我们暂时将连接这些主机的无路由器网络表示为云,并在第 6 章和第 7 章中深入研究此类网络的内部结构
在 IP 术语中,该网络互连三个主机接口和一个路由器接口形成一个子网。 (子网也称为 IP 网络或简称为网络)
223.1.1.0/24:
- /24: 子网掩码,表示32位数量的最左边24位定义
子网地址
从上面的讨论可以清楚地看出,具有多个以太网段和点对点链路的组织将拥有多个子网,给定子网上的所有设备都具有相同的子网地址。
原则上,不同的子网可以具有完全不同的子网地址。但实际上,它们的子网地址通常有很多共同点。为了理解其中的原因,接下来让我们将注意力转向互联网中如何处理寻址。
互联网的地址分配策略称为无类别域间路由CIDR 。
CIDR 泛化了子网寻址的概念。与子网寻址一样,32 位 IP 地址分为两部分,并再次采用点分十进制形式 a.b.c.d/x,其中 x 表示地址第一部分的位数。
a.b.c.d/x
- 地址的 x 个最高有效位构成 IP 地址的网络部分,通常称为地址的前缀(或
网络前缀)。通常会为组织分配一个连续地址块,即具有公共前缀的一系列地址。在这种情况下,组织内的设备的 IP 地址将共享公共前缀。当外部路由器转发此子网中的数据时,就只需考虑网络前缀就可以进入到此子网中,而不用考虑后面的位。
- 地址的其余 32-x 位识别组织中的设备(主机部分),所有设备都具有相同的网络前缀。这些是在组织内的路由器上转发数据包时要考虑的位。这些低阶位可以(或可以不)具有额外的子网划分结构。
例如,假设地址 a.b.c.d/21 的前 21 位指定组织的网络前缀,其余 11 位则标识组织中的特定主机。
但可以继续用这11个主机位,继续划分子网:
- a.b.c.d/24:前24位都是属于子网,只有后8位标识主机。
- a.b.c.d/30:前30位都是属于子网,只有后两位标识主机。
地址聚合(路由聚合、路由汇总)
通过ISP的无分类编址,使得同一组织内的所有主机都通过最大的IP地址来寻址,内部细节不需要外界路由器关心。
这种使用单个前缀(分配给组织的那个顶级子网)通告多个网络(组织内部细分的许多网络)的能力通常称为地址聚合(也称为路由聚合或路由汇总)
广播地址
如果我们没有提到另一种类型的 IP 地址,即 IP 广播地址 255.255.255.255,那就是我们的失职。当主机发送目标地址为 255.255.255.255 的数据报时,该消息将传递到同一子网上的所有主机。路由器也可以选择将消息转发到相邻子网(尽管它们通常不这样做)
组织如何获得一组地址
一个组织或者企业如何获取一组用于本组织内部的IP地址呢?
获取主机地址:动态主机配置协议( DHCP)
一旦组织获得了地址块,它就可以将单独的 IP 地址分配给组织中的主机和路由器接口。
路由器中的IP地址通常是手动配置的(通常使用网络管理工具进行远程配置)
主机地址也可以手动配置,但这通常是使用动态主机配置协议(DHCP)[RFC 2131]完成的。
DHCP 允许主机自动获取(分配)IP 地址。网络管理员可以配置 DHCP,以便给定主机每次连接到网络时都会收到相同的 IP 地址,或者可以为主机分配一个临时 IP 地址,该地址每次连接到网络时都会有所不同。
除了主机 IP 地址分配之外,DHCP 还允许主机了解其他信息
- 子网掩码、
- 第一跳路由器的地址(通常称为默认网关)
- 本地 DNS 服务器的地址。
DHCP 是一种客户端-服务器协议。客户端通常是想要获取网络配置信息的新到达的主机。
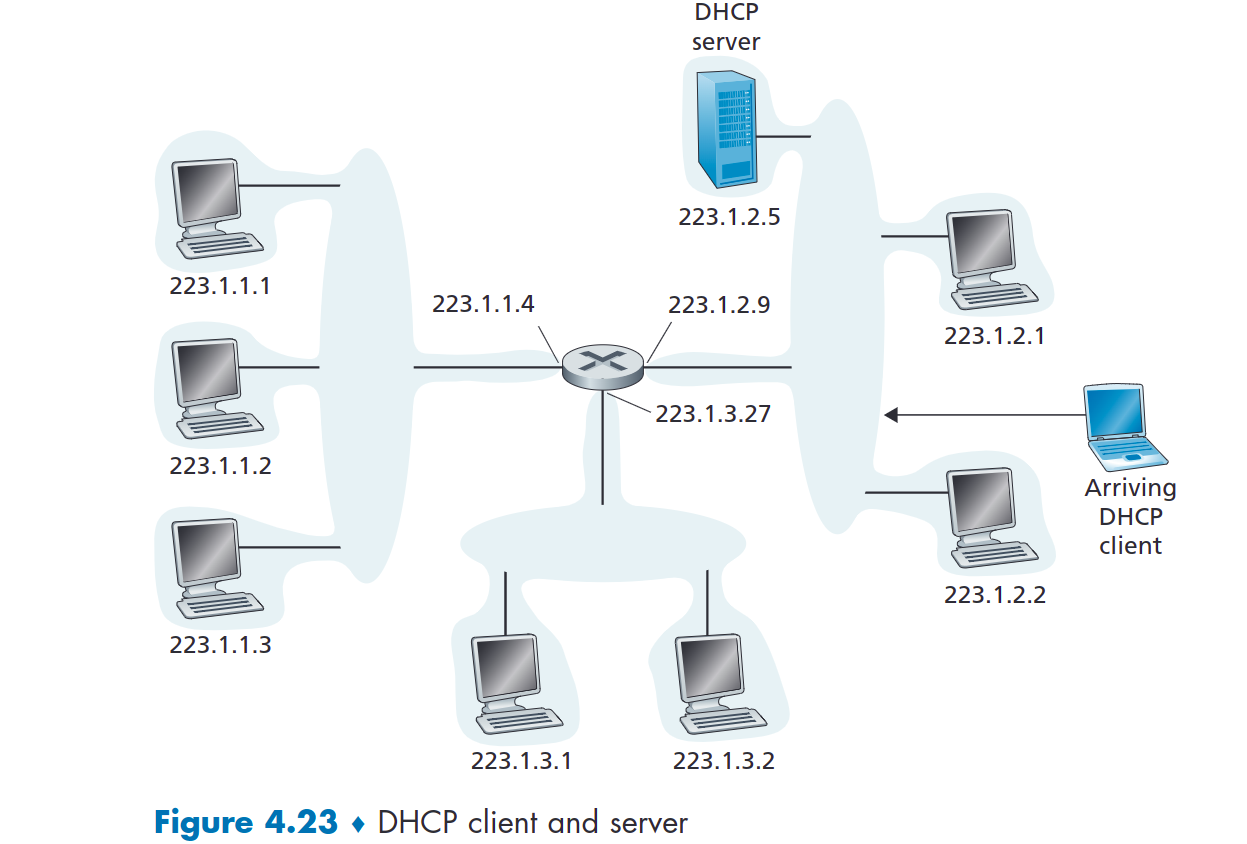
在最简单的情况下,每个子网都有一个 DHCP 服务器。如果子网上没有服务器,则需要有DHCP服务器的中继代理(通常是路由器)。图 4.23 显示了连接到子网 223.1.2/24 的 DHCP 服务器,路由器充当连接到子网 223.1.1/24 和 223.1.3/24 的到达客户端的中继代理。在下面的讨论中,我们假设子网上有 DHCP 服务器可用。
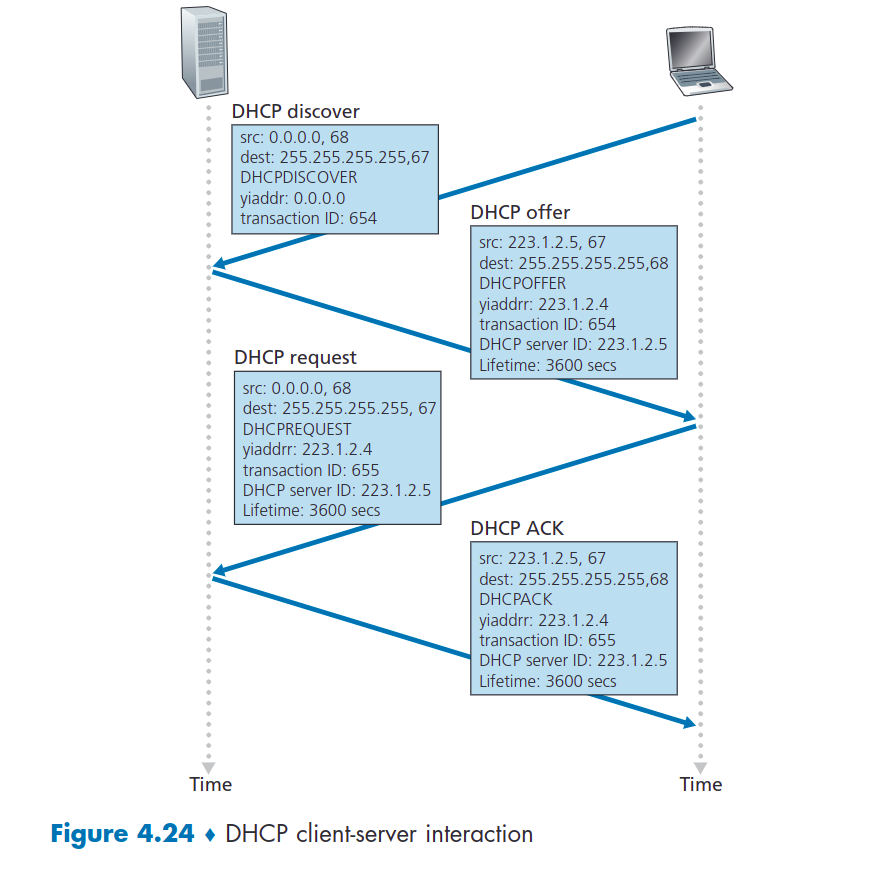
对于新到达的主机,DHCP 协议是一个四步过程,如图 4.24 所示,网络设置如图 4.23 所示。在此图中,yiaddr(如“您的互联网地址”)表示分配给新到达的客户端的地址。这四个步骤是:
- DHCP 服务器发现:找到与客户端交互的DHCP服务器。通过发送
DHCP发现消息完成的(UDP协议):
- 由于此时不知道目的IP,自己也没有IP。
- 所以发送源IP为
0.0.0.0目的IP为255.255.255.255的广播,发现DHCP服务器。
- DHCP 服务器提供者:
- 收到发现消息的服务器也会发送一个
DHCP offer message,这个消息也是一个广播消息。(因为新客户端没有被分配IP,所以只能广播)。
- 通常会有多个服务器响应客户端,从而各自发送这条消息。
- DHCP 请求:
- 客户端在收到(数条)提供者的回应信息之后,选择其中一个,向他发送
DHCP request message。
- DHCP ACK
- 服务器用
DHCP ACK message响应 DHCP 请求消息,确认请求的参数。
网络地址转换
支持 NAT 的路由器在外界看来并不像路由器。相反,NAT 路由器对于外界来说就像具有单个 IP 地址的单个设备。
本质上,启用 NAT 的路由器向外界隐藏了家庭网络的详细信息。
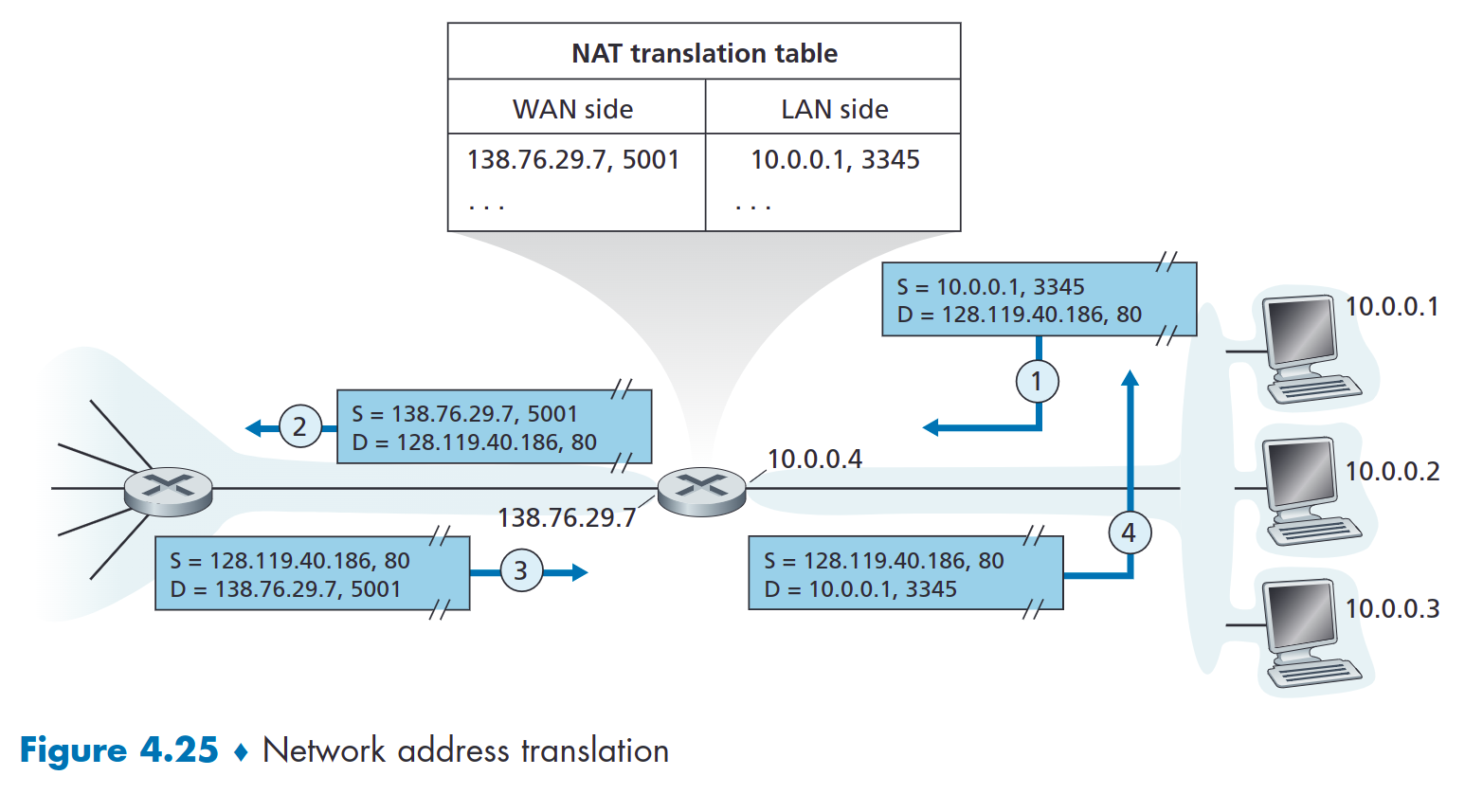
如果从 WAN 到达 NAT 路由器的所有数据报都具有相同的目标 IP 地址,那么路由器如何知道应将数据转发到哪个内部主机?技巧是在 NAT 路由器上使用 NAT 转换表,并在表条目中包含端口号和 IP 地址。
考虑图 4.25 中的示例。假设位于主机 10.0.0.1 后面的家庭网络中的用户请求 IP 地址为 128.119.40.186 的某个 Web 服务器(端口 80)上的网页。主机 10.0.0.1 分配了源端口号 3345 并将数据报发送到 LAN。 NAT路由器收到数据报后,为该数据报生成新的源端口号5001,并用其WAN侧IP地址138.76.29.7替换源IP地址,并用新的源端口号5001替换原来的源端口号3345。当生成新的源端口号时,NAT 路由器可以选择当前不在 NAT 转换表中的任何源端口号。 (请注意,由于端口号字段为 16 位长,因此 NAT 协议可以通过路由器的单个 WAN 侧 IP 地址支持超过 60,000 个同时连接!)路由器中的 NAT 还会在其 NAT 转换表中添加一个条目。 Web 服务器完全没有意识到包含 HTTP 请求的到达数据报已被 NAT 路由器操纵,它以目标地址为 NAT 路由器的 IP 地址、目标端口号为 5001 的数据报进行响应。当该数据报到达时在 NAT 路由器处,路由器使用目标 IP 地址和目标端口号索引 NAT 转换表,以为家庭网络中的浏览器获取适当的 IP 地址(10.0.0.1)和目标端口号(3345)。然后路由器重写数据报的目标地址和目标端口号,并将数据报转发到家庭网络。
近年来,NAT 得到了广泛的部署。但 NAT 也并非没有批评者。首先,有人可能会争辩说,端口号旨在用于寻址进程,而不是用于寻址主机。这种违规确实会给在家庭网络上运行的服务器带来问题,因为正如我们在第 2 章中所看到的,服务器进程在众所周知的端口号处等待传入请求,P2P 协议中的对等点在充当服务器时需要接受传入连接。一个对等点如何连接到位于 NAT 服务器后面且具有 DHCP 提供的 NAT 地址的另一个对等点?
在P2P应用程序中,任何参与对等方A应当能够对任何其他参与的对等方B发起一条TCP连接。所以该问题实质在于,如果对等方B在一个NAT后面,那么它将不能充当服务器并接受TCP连接。(A单独无法得知B的地址)
现在假设对等方A不在NAT后面,对等方B在NAT后面,对等方C不在NAT后面。C与B已经创建了一条TCP连接,如果A想与B创建连接,则需要通过C请求对等方B,发起直接返回对等方A的一条TCP连接。一旦二者建立一条直接的P2P TCP连接,两个对等方就可以交换报文或文件了。
这种雇佣关系被称为连接反转(connection reversal),已被许多P2P应用程序用于NAT穿越(NAT traversal)。
若A,B二者都在NAT后面则可使用应用程序进行中继处理。
IPV6