概述
如果操作系统崩溃或电源故障,系统主内存的内容可能会丢失。相比之下,非易失性存储是持久的,并且在崩溃和断电时仍能保持其状态。非易失性存储还具有更高的容量和更低的成本。
然而,非易失性存储技术有其自身的缺点。
- 例如,当前的非易失性存储技术(例如磁盘和高密度闪存存储)不允许随机访问单个存储字;相反,访问必须以更粗粒度的单位进行——一次 512、2048 或更多字节。
- 此外,这些访问可能比访问 DRAM 慢得多;
这种巨大的差异(在旋转磁盘的情况下约为五个数量级)促使操作系统以不同于主内存的方式组织和使用持久存储设备。
文件系统是一种常见的操作系统抽象,允许应用程序访问非易失性存储。文件系统使用多种技术来应对非易失性存储设备的物理限制并为用户提供更好的抽象。例如,图 11.1 总结了物理特性如何激发文件系统设计的几个关键方面:
| 目标 | 物理特点 | 设计影响 |
|---|---|---|
| 高性能 | 发起IO访问成本大 | 使用文件、目录、可用空间位图和放置试探法组织数据放置,以便以大型连续单元访问存储 缓存以避免访问持久存储 |
| 命名的数据 | 存储容量大,不会崩溃,并且可以在程序之间共享 | 支持具有有意义名称的文件和目录 |
| 受控制的共享 | 设备存储大量用户数据 | 在文件中包含访问控制元数据 |
| 可靠存储 | 1.更新期间可能会发生崩溃 2. 存储设备可能会发生故障 3.闪存单元可能会磨损 |
1.使用事务使一组更新成为原子的 2.使用冗余来检测和纠正故障 3.将数据移动到不同的存储位置以均匀磨损 |
- 性能:文件系统通过对数据的放置位置进行分组来分摊启动昂贵操作的成本,例如移动磁盘臂或擦除固态内存块,以便此类操作访问大范围的连续存储
- 名字:文件系统将相关数据分组到目录和文件中,并为它们提供人类可读的名称(例如,/home/alice/Pictures/summer-vacation/hiking.jpg。)即使在创建文件的程序退出之后,这些数据名称仍然有意义它们帮助用户组织大量存储,并且使用户可以轻松地使用不同的程序来创建、读取和编辑数据。
- 受控共享。文件系统包括有关谁拥有哪些文件以及允许哪些其他用户读取、写入或执行数据和程序文件的元数据
- **可靠性:**文件系统使用事务以原子方式更新多个持久存储块,类似于操作系统如何使用临界区以原子方式更新内存中的不同数据结构
为了获得良好的性能和可接受的可靠性,应用程序编写者和操作系统设计者都必须了解存储设备和文件系统的工作原理。本章和接下来的三章讨论关键问题:
其余部分通过描述典型的 API 和抽象集来介绍文件系统,并概述提供这些抽象的软件层
文件系统抽象
文件系统抽象有两个关键部分:定义数据集的文件和定义文件名称的目录。
- 文件。文件是文件系统中命名的数据集合。
- 文件的信息有两部分:元数据和数据。文件的元数据是操作系统理解和管理的有关文件的信息。例如,文件的元数据通常包括文件的大小、修改时间、所有者及其安全信息,例如文件是否可以由所有者或其他用户读取、写入或执行
- 文件的数据可以是用户或应用程序放入其中的任何信息。从文件系统的角度来看,文件的数据只是一个无类型字节数组。
通常,操作系统将文件的数据视为无类型字节数组,将其留给应用程序来解释文件的内容。然而,有时操作系统需要能够解析文件的数据。例如,Linux 支持许多不同的可执行文件类型,例如 ELF 和 a.out 二进制文件以及 tcsh、csh 和 perl 脚本。Linux 通过让可执行文件以标识文件格式的幻数开头来实现此目的。例如,ELF 二进制可执行文件以四个字节 0x7f、0x45、0x4c 和 0x46(ASCII 字符 DEL、E、L 和 F)开头
- 目录。文件包含系统定义的元数据和任意数据,而目录提供文件的名称。特别是,文件目录是人类可读名称的列表以及从每个名称到特定底层文件或目录的映射。
Volume卷(分区):
文件系统是以分区为单位来进行管理的:
- 不同的分区都有各自独立的文件系统。一台计算机可以通过在
单个逻辑层次结构(目录层次结构)中挂载(安装)多个卷来利用多个卷上存储的文件系统。 - 分区是逻辑磁盘的抽象。
- 一个磁盘可以对应一个分区
- 一个磁盘也可以对应多分区。每个分区可以使用各自的文件系统组织数据。
- 多个磁盘也可以对应一个分区。使得文件系统跨物理磁盘管理
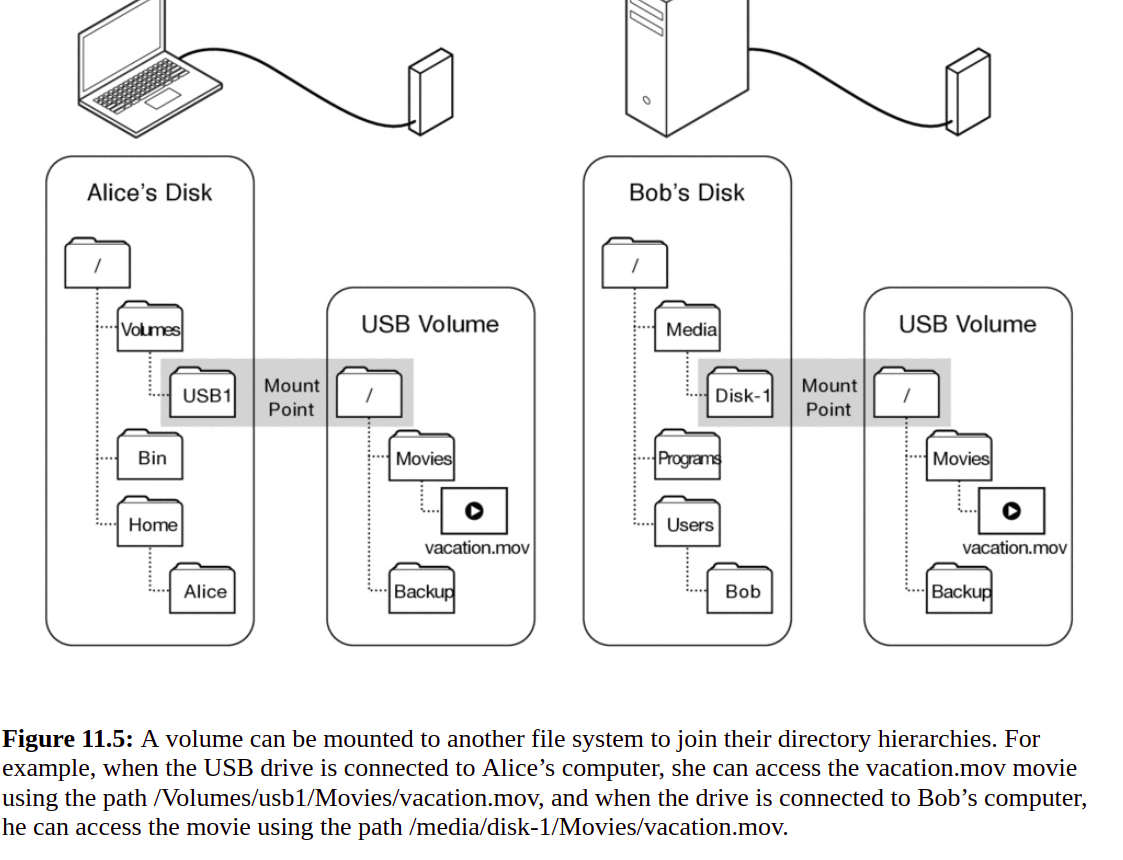
例如,假设 USB 驱动器包含一个带有目录 /Movies 和 /Backup 的文件系统,如图 11.4 所示。如果 Alice 将该驱动器插入她的笔记本电脑,笔记本电脑的操作系统可能会使用路径 /Volumes/usb1/ 挂载 USB 卷的文件系统,如图 11.5 所示。然后,如果 Alice 调用 open(“/Volumes/usb1/Movies/vacation.mov”),她将从 USB 驱动器卷上的文件系统中打开文件 /Movies/vacation.mov。相反,如果 Bob 将该驱动器插入他的笔记本电脑,则笔记本电脑的操作系统可能会使用路径 /media/disk-1 挂载卷的文件系统,并且 Bob 将使用路径 /media/disk-1/Movies 访问同一文件/vacation.mov。
API
文件系统的软件层次
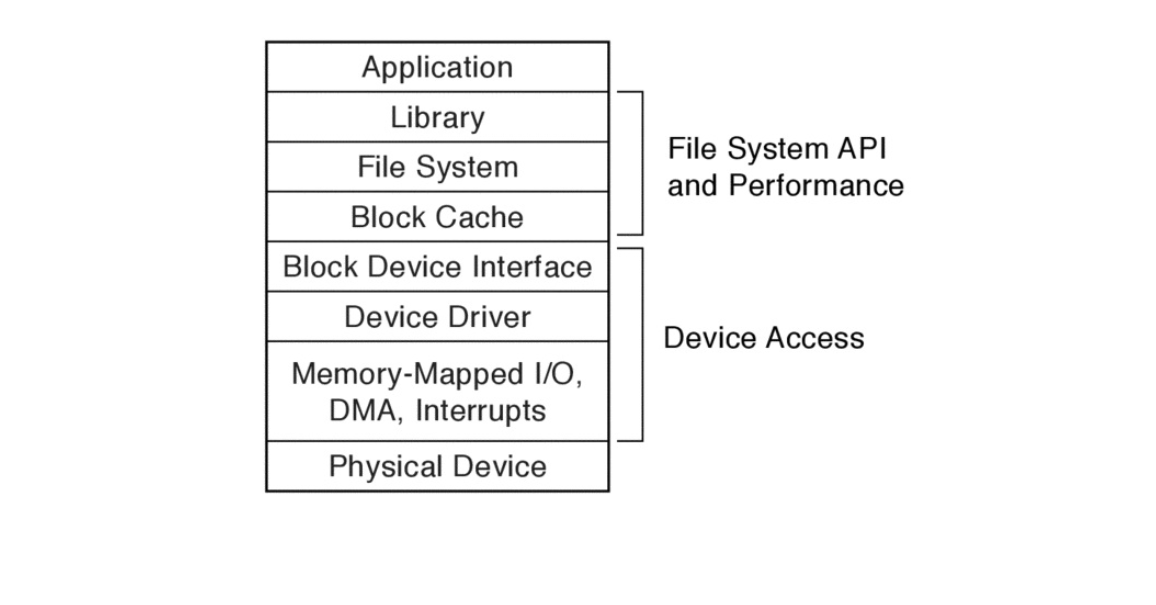
如图11.7所示,操作系统通过一系列软件层来实现文件系统抽象。从广义上讲,这些层有两组任务:
- 向上 提供API给用户 软件堆栈的顶层——库、内核级文件系统和内核的块缓存——提供了一个方便的API来访问命名文件,并通过缓存、写缓冲(延迟写,回写)和预取来最大限度地减少缓慢的存储访问
- 向下 提供设备访问。 软件堆栈的较低级别为操作系统提供了访问各种 I/O 设备的方法。 设备驱动程序通过为每个设备提供专用于此硬件的代码,并将该代码放置在操作系统其余部分可以使用的更简单、更通用的接口(例如块设备接口)后面,隐藏特定 I/O 硬件的详细信息。设备驱动程序使用系统的主处理器和内存作为正常的内核级代码执行,但它们(CPU和内存)必须与 I/O 设备交互。系统的处理器和内存使用内存映射 I/O、DMA 和中断与其 I/O 设备进行通信。
在其余部分中,我们首先讨论文件系统 API 和性能层。然后我们讨论设备访问。
API
文件系统软件堆栈的顶层(分为应用程序库和操作系统内核代码)提供文件系统 API,并提供缓存和写入缓冲以提高性能。
- 系统调用和库。文件系统抽象(如图 11.6 所示的 API)可以直接由系统调用提供。或者,应用程序库可以包装系统调用以添加附加功能,例如缓冲(系统调用IO和标准库IO就这样)
- 后者(c库函数)的优点是该库包含缓冲区,可将程序的小型读取和写入聚合到访问较大块的系统调用中,从而减少开销。例如,如果程序使用库函数 fread() 读取 1 个字节的数据,则 fread() 实现可以使用 read() 系统调用将更大的数据块(例如 4 KB)读取到维护的缓冲区中通过应用程序地址空间中的库。然后,如果进程再次调用 fread() 来读取另一个字节,则库只需从缓冲区返回该字节,而无需执行系统调用。
- 块缓存 Block cache:典型的存储设备比计算机的主内存慢得多。因此,操作系统的块缓存会缓存最近读取的块,并缓冲最近写入的块,以便稍后将它们写回存储设备。
- 除了通过缓存和写缓冲提高性能之外,块缓存还充当同步点:因为对给定块的所有请求都经过块缓存,所以操作系统在每个缓冲区缓存条目中包含信息,例如,阻止进程在另一个进程写入块时读取该块,或者确保给定的块仅从存储设备中获取一次,即使它被许多进程同时读取。
- 预取Prefetching。操作系统使用预取来提高 I/O 性能。例如,如果进程读取文件的前两个块,操作系统可能会预取接下来的十个块
设备驱动程序:通用抽象
设备驱动程序在操作系统实现的高级抽象与I/O设备的硬件特定细节之间转换。
操作系统可能必须处理许多不同的I/O设备。
例如,笔记本电脑可能连接到两个键盘(一个内部和一个外部),触控板,一只鼠标,一个有线以太网,无线802.11网络,一个无线蓝牙网络,两个磁盘驱动器(一个内部和一个磁盘驱动器(一个外部),麦克风,扬声器,相机,打印机,扫描仪和USB拇指驱动器。这只是当今可以连接到计算机的数千台设备中的少数。构建一个分别处理每种情况的操作系统将是不可能的。
分层提供了访问各类设备的通用方法,有助于简化操作系统。例如,对于任何给定的操作系统,存储设备驱动程序通常实现标准块设备接口,允许以固定大小的块(例如,512、2048 或 4096 字节)读取或写入数据。
在标准块设备接口上运行的文件系统可以将文件存储在任何存储设备上,只要该存储设备的驱动程序实现了该接口,无论是 Seagate 旋转磁盘驱动器、Intel 固态驱动器、Western Digital RAID 还是 Amazon Elastic Block Store 卷。这些设备都有不同的内部组织和控制寄存器,但如果每个制造商都提供导出标准接口的设备驱动程序,则操作系统的其余部分无需关心这些每个设备的详细信息
设备访问
操作系统的设备驱动程序应如何与存储设备通信并控制存储设备?乍一看,存储设备似乎与我们迄今为止讨论的内存和 CPU 资源有很大不同。例如,磁盘驱动器包括多个电机、用于读取数据的传感器和用于写入数据的电磁体。
内存映射IO (还有个端口映射IO)
端口映射IO:提供额外的 I/O 指令
内存映射 I/O(memory- mapped I/O):硬件将设备寄存器作为内存地址提供。
端口映射 I/O 在物理内存地址受限的体系结构中非常有用,因为 I/O 设备不需要消耗物理内存地址范围。另一方面,对于具有足够大物理地址空间的系统,内存映射 I/O 可以更简单,因为不需要定义新指令或地址范围,并且设备驱动程序可以使用任何标准内存访问指令来访问设备。此外,内存映射 I/O 提供了更统一的模型来支持 DMA—-I/O 设备和主存之间的直接传输
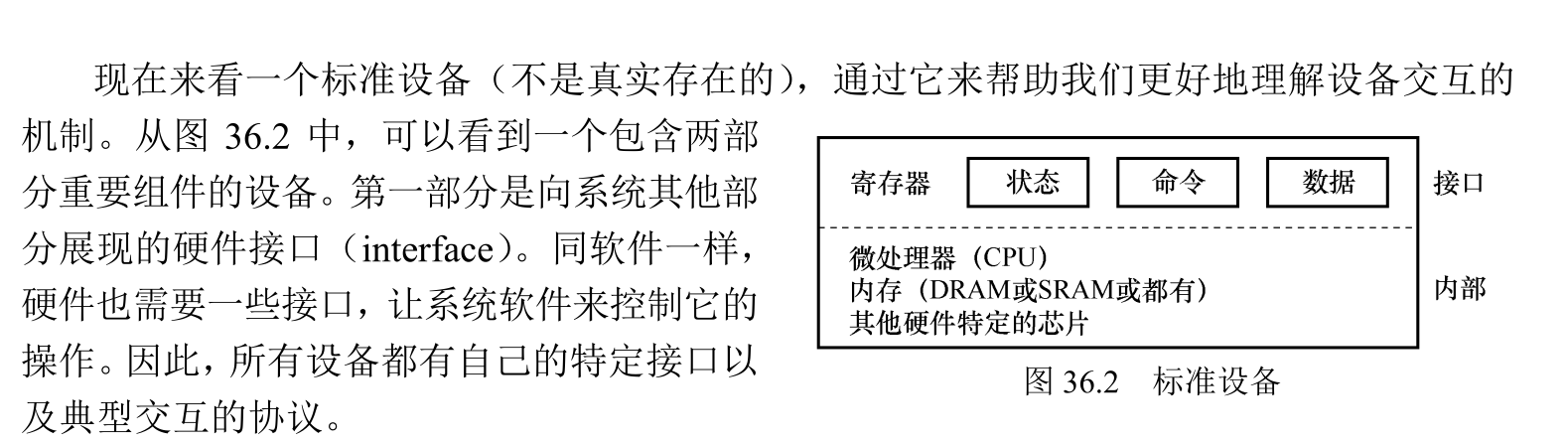
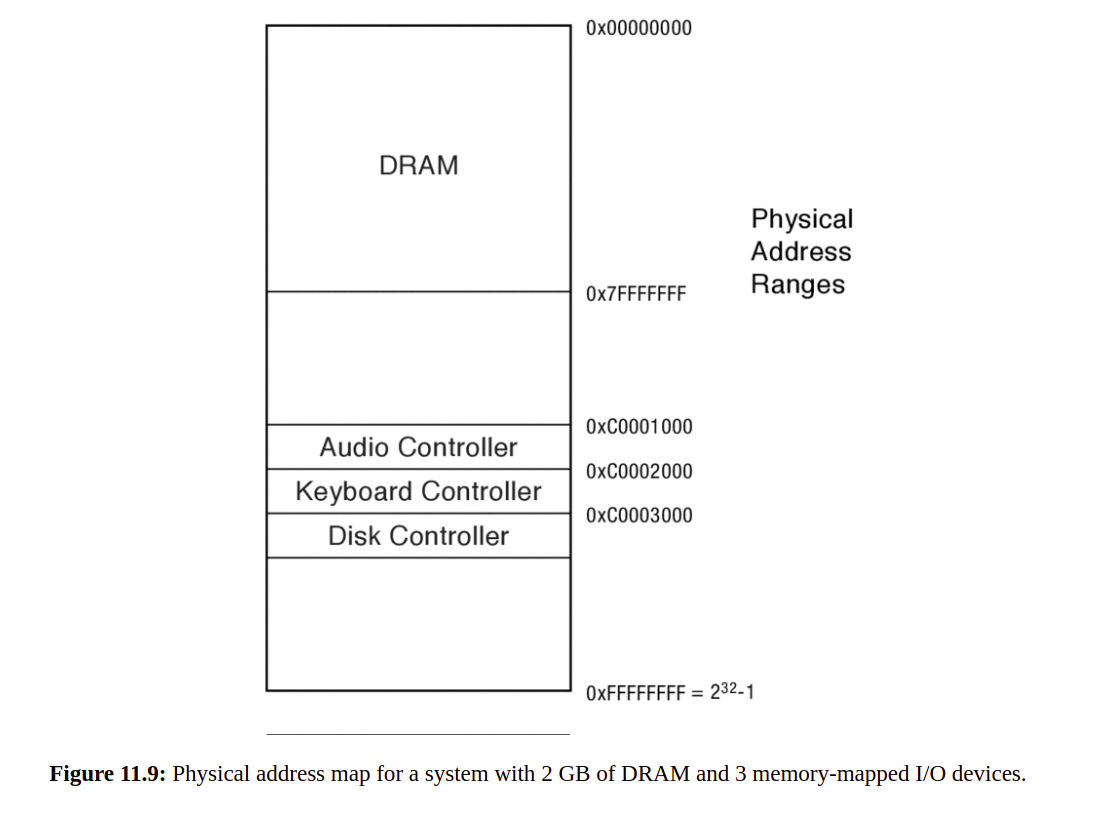
每个 I/O 设备都有一个带有一组寄存器的控制器,可以写入和读取这些寄存器,以将命令和数据传输到设备或从设备传输命令和数据。例如,一个简单的键盘控制器可能有一个寄存器,可以通过读取该寄存器来了解最近按下的按键,以及另一个可以写入的寄存器来打开或关闭大写锁定灯。为了允许读写 I/O 控制寄存器,系统实现了内存映射 I/O。内存映射 I/O 将每个设备的控制寄存器映射到内存总线上的一系列物理地址。 CPU 对此物理地址范围的读取和写入不会进入主内存。相反,它们会访问 I/O 设备控制器上的寄存器。
DMA
许多 I/O 设备(包括大多数存储设备)都会批量传输数据。例如,操作系统不会从磁盘读取一两个字,它们通常一次至少传输几千字节。 I/O 设备可以使用直接内存访问,而不是要求 CPU 读取或写入大量传输的每个字。当使用直接内存访问 (DMA) 时,I/O 设备在其自己的内存和系统主内存之间复制数据块。为了设置 DMA 传输,简单的操作系统可以使用内存映射 I/O 来向设备提供目标物理地址、传输长度和操作代码。然后,设备将数据复制到目标地址或从目标地址复制数据,而无需额外的处理器参与。设置 DMA 传输后,在 DMA 传输完成之前,操作系统不得将目标物理页用于任何其他目的。因此,操作系统将目标页面“固定”在内存中,以便在取消固定之前无法重用它们。例如,固定的物理页无法交换到磁盘,然后重新映射到其他虚拟地址。
为了设置 DMA 传输,简单的操作系统可以使用内存映射 I/O 来向设备提供目标物理地址、传输长度和操作代码。然后,设备将数据复制到目标地址或从目标地址复制数据,而无需额外的处理器参与。设置 DMA 传输后,在 DMA 传输完成之前,操作系统不得将目标物理页用于任何其他目的。因此,操作系统将目标页面“固定”在内存中,以便在取消固定之前无法重用它们。例如,固定的物理页无法交换到磁盘,然后重新映射到其他虚拟地址
中断
操作系统需要知道 I/O 设备何时完成对请求的处理或者新的外部输入何时到达。一种选择是轮询,即重复使用内存映射 I/O 来读取设备上的状态寄存器。由于 I/O 设备通常比 CPU 慢得多,并且 I/O 设备接收的输入可能以不规则的速率到达,因此 I/O 设备通常最好使用中断来通知操作系统重要事件
将它们放在一起:简单的磁盘请求
当进程发出像 read() 这样的系统调用来将数据从磁盘读取到进程的内存中时,操作系统会将调用线程移至等待队列。然后,操作系统使用内存映射 I/O 来告诉磁盘读取请求的数据并设置 DMA,以便磁盘可以将该数据放入内核内存中。然后磁盘读取数据并将其 DMA 到主内存中;一旦完成,磁盘就会触发中断。然后,操作系统的中断处理程序将数据从内核缓冲区复制到进程的地址空间中。最后,操作系统将线程移动到就绪列表中。当线程下次运行时,它将从系统调用中返回,数据现在存在于指定的缓冲区中。